
A decision engine for regulated work.
For work that can't be wrong. Pandotic reads the most complex, regulated documents in your field — and tells your experts where they stand against the rules that matter, and what to do about it. Every call backed by evidence, scored for confidence, built to be defended.
Pandotic connects AI to your domain.
It doesn't build a competing one.
The model is configuration, not architecture. We build the decision layer on top of the world's best AI — not a replacement for it. Claude, GPT, Gemini, open-source models, or any combination sit under the engine. As better models ship, the engine updates. No lock-in, no proprietary LLM, no competing with your existing AI investments.
ChatGPT can't do this work. Neither can a custom LLM bolted to your database.
Every regulated team tries the same two things first. A generic chatbot invents answers from memory. A custom model over your own documents retrieves and sounds fluent — but still can't cite the rulebook, do the math, or be corrected. Neither produces something an expert will put their name on.
The first two are built to sound right. Regulated work needs one built to be right — and prove it.
Why grounding matters
A knowledge base isn't a pile of documents in a chatbot.
The most common question we get: “can't I just upload our documents to an LLM?” You can — and for regulated work, that's exactly where it breaks. Here's the difference.
A pile of documents in an LLM
- ✕Everything weighs the same. A forum post and a federal regulation are retrieved as equals — the model can't tell authority from anecdote.
- ✕Frozen at upload. It knows whatever you pasted, whenever you pasted it. Codes change; the pile doesn't.
- ✕No version or jurisdiction sense. v4 vs v4.1, your state vs another — it can't keep them straight.
- ✕Retrieval by vibes. Similarity search grabs passages that sound related, then the model fills the gaps — confidently.
- ✕No precedence when sources conflict. When two documents disagree, nothing decides which one wins.
A governed knowledge base
- ✓Ranked by authority. Law outranks standard outranks policy outranks anecdote — every time.
- ✓Version & jurisdiction aware. The engine knows which edition and which region governs this case.
- ✓Cited to the source. Every claim traces back to the exact rule it rests on — checkable, auditable.
- ✓Current & maintained. As regulations change, the knowledge base updates — not a frozen snapshot.
- ✓Conflicts resolved by precedence. When sources disagree, the hierarchy decides which one controls.
A pile of documents can tell you what a paragraph says. A governed knowledge base can tell you what actually governs your decision — and prove it.
How the engine works
From your documents to something you can act on.
One pipeline, every product. Ground it in what's true, read the hard documents, and turn the evidence into the tool the job actually needs.
Knowledge base
Everything the engine is allowed to treat as true — your world, plus the rules that govern it.
Document & complex-data extraction
The engine reads the artifacts your experts read — and turns them into structured, scored evidence.
- Ingest complex docs, drawings, models & data
- Structured evidence with confidence
- Score every requirement against the framework
- Deterministic checks where the numbers matter
Ground it, read it, decide.
One system in three layers. Each is a reason to trust it.
The knowledge base — your data and the rulebook
The foundation has two halves, and the second is the moat. Internal: your own data, history, and institutional knowledge. External: the codified authority your field answers to — LEED, IDEA, GRI/SASB/CSRD, an RFP rubric, building code. The engine treats authority as authority and anecdote as anecdote.
The analysis engine — reading what's actually hard
A genuinely complex, domain-specific artifact gets read at a depth no one can sustain across a stack of them. Layered moderation on intake; many specialized agents in parallel; every requirement scored against the evidence; and where the artifact has structure, it's parsed and checked with deterministic code — not model guesswork.
The decision layer — output a professional will sign
The output has structure. Every verdict carries its supporting evidence and a confidence level. A recommendation or compliance path comes attached. Any value is expert-correctable, and the override propagates so the whole analysis stays consistent. An advisor explains it in plain language.
The knowledge base is the floor — not the product.
Anyone can index a corpus and bolt on a chatbot. That gets you recall. It does not get you a verdict you can defend in front of a regulator, a client, or a court. The KnowledgeEngine is the system built on top of that floor — six reusable capabilities that turn a knowledge base into a product.
Go deeper into the engine →One engine. Every regulated field.
Every field is the same motion — only the rulebook, the artifact, and the output change. Pick a field to see how the engine points at it.
Green building
Green-building submittals + energy models — the hardest artifacts in the field.
Get certified, credit by credit — with the evidence to defend every call to the reviewer.
See it in production. LEEDSmart, today.
Green-building submittals in; credit-by-credit verdicts with evidence and confidence out; the energy model QA'd deterministically; an advisor that explains it all. Drag or step through the live product.

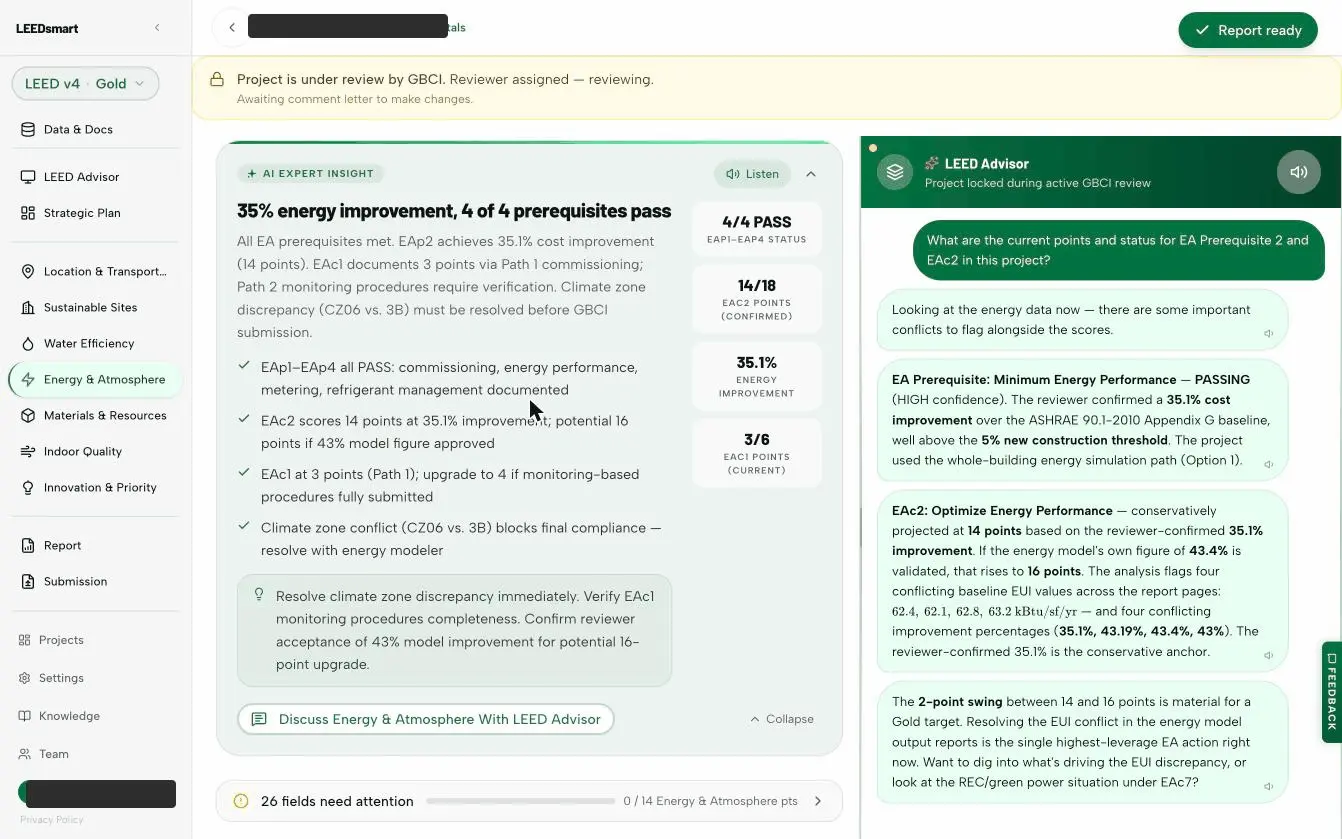
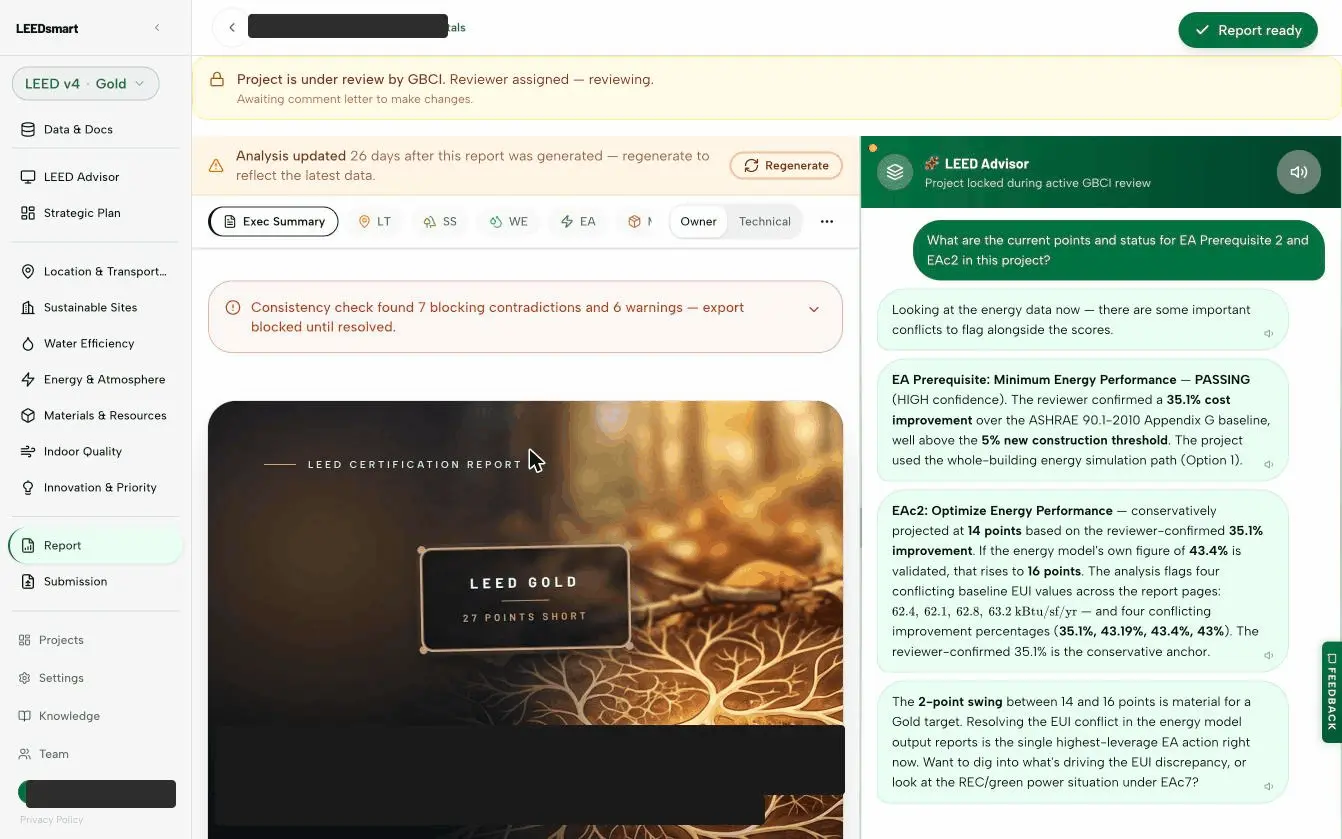
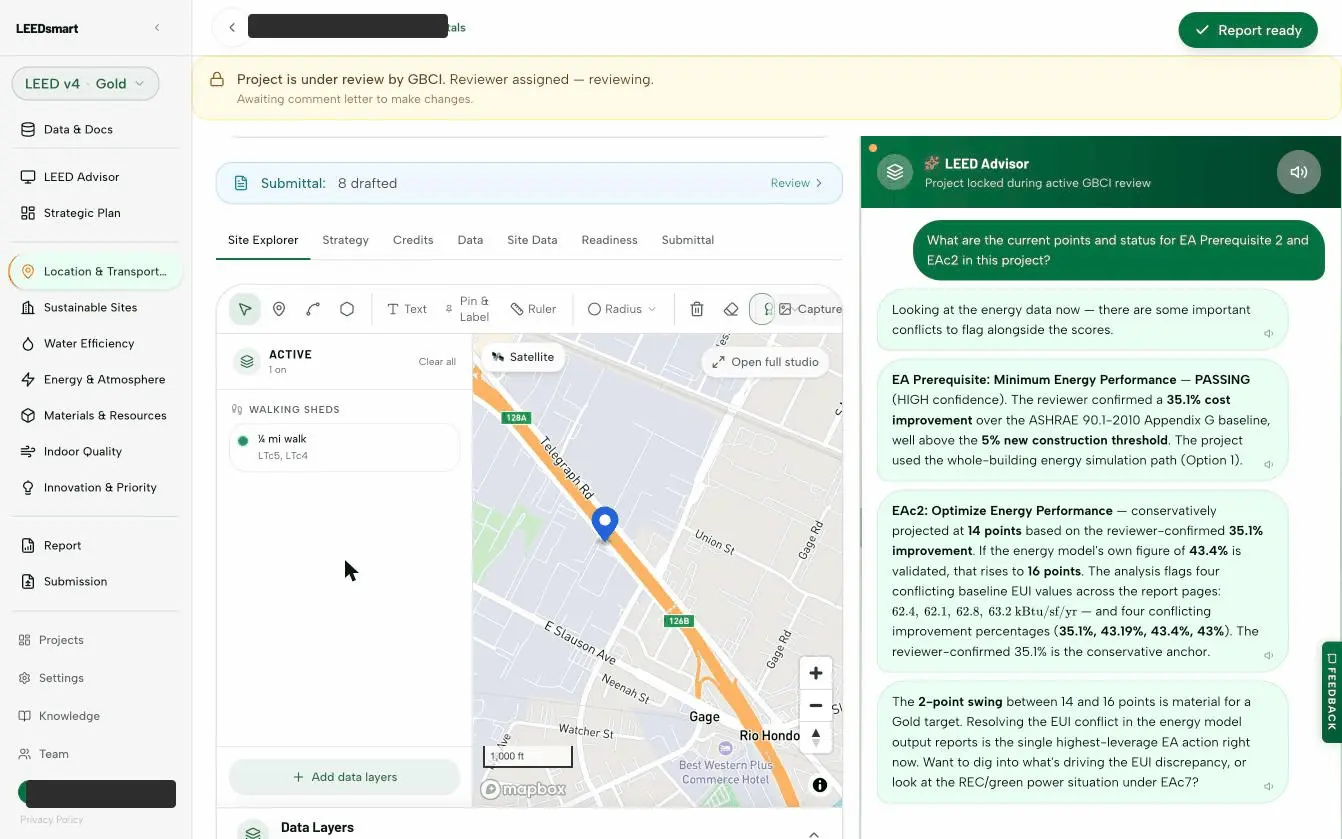
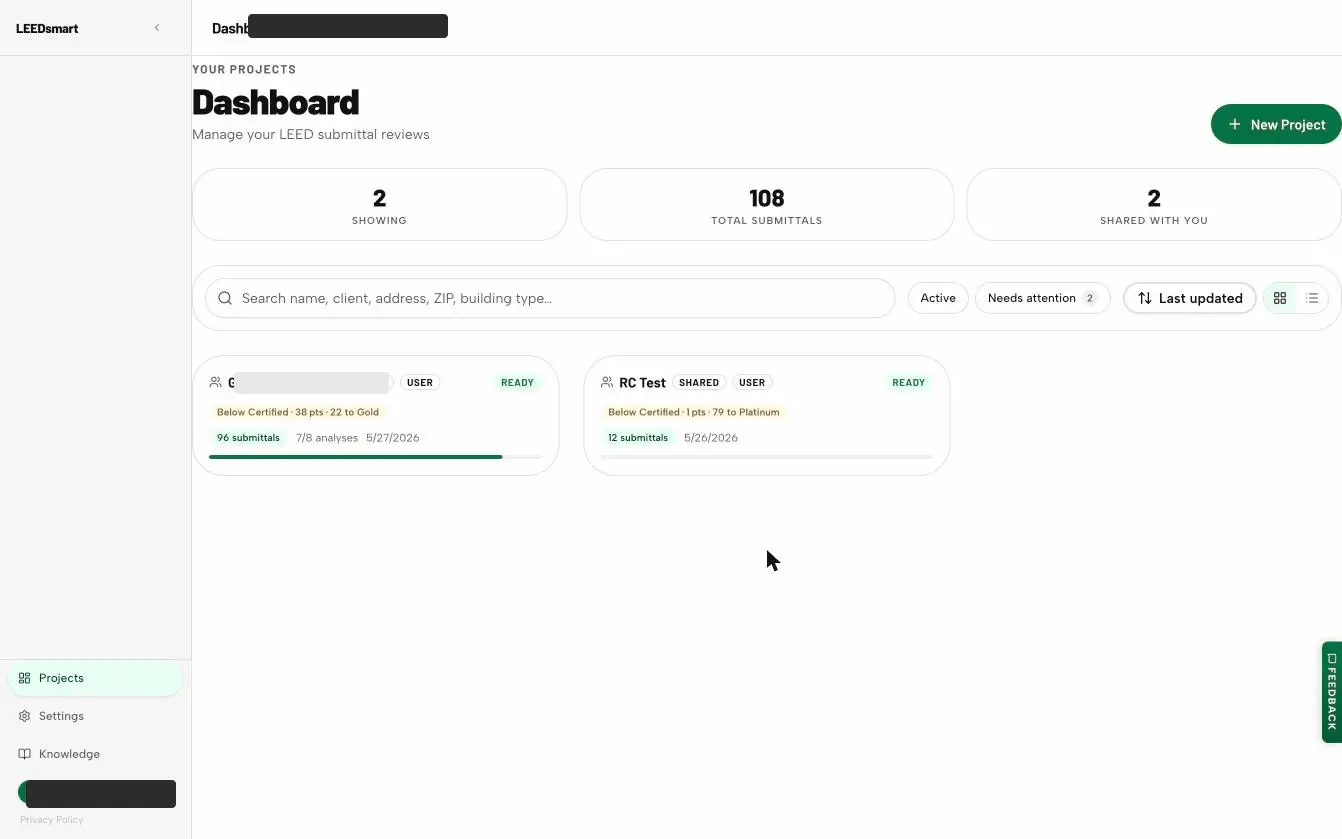
Model-agnostic. Source-transparent. Always current.
A decision engine you can trust is one you can verify, own, and keep current. Ours isn't locked to a model, a vendor, or a frozen snapshot of the world.
Works with any LLM
The model is configuration, not architecture. Combine frontier and open models, swap them as better ones ship — Claude, GPT, Gemini, or open source. No lock-in.
Runs on your stack
Your cloud or your intranet. Your data stays inside your boundary — the engine comes to the data, not the other way around.
Grounded in public truth
Built on public sources, laws, codes, and the standards your field answers to — version-correct, jurisdiction-aware, and cited so every call can be checked.
Constantly upgraded
As models advance and regulations change, the engine and its knowledge base update with them. You're always on the latest — not last year's snapshot.
We don't hand you a tool. We build the system around your problem.
The engine is the platform. The engagement is how we point it at your world — your data, your regulatory environment, your process. For an organization, an industry, or a consultant, we build the whole thing with you.
Build your knowledge base
We assemble your institutional data and the regulatory environment you operate in — laws, codes, standards, rubrics — into one grounded, version-correct source of truth.
Onboard your process & criteria
We sit with your experts to capture how you actually work — your workflow, your evaluation criteria, your edge cases — so the engine reasons the way your best people do.
Ship custom software
We build the product and the processes around it — tuned to your problem, running in production, owned by you and upgraded as your field changes.
The engine is the platform; the engagement is how we point it at your world. One partner, from knowledge base to working software.
Grounded. Defensible. Built for complexity.
Grounded
Every output is anchored in your data and the current, version-correct rulebook — and cites the evidence for each call. It can't invent a regulation it isn't holding.
Defensible
Verdict, evidence, and confidence on every requirement; deterministic math; an expert override that recalculates; a full audit trail. Built to show its work.
Built for complexity
It reads the artifacts your experts read — energy models, IEPs, floor plans, bid books, license stacks — at a depth no one can sustain across a stack of them.

Tell us the documents and the rulebook.
We'll point the engine at it.
A pilot proves a single framework fast — the shortest path from “could AI do this?” to a verdict your experts will sign.